12. Continuous Integration
METplus utilizes GitHub Actions to run processes automatically when changes are pushed to GitHub. These tasks include:
Building documentation to catch warnings/errors
Building a Docker image to run tests
Creating/Updating Docker data volumes with new input data used for tests
Running unit tests
Running use cases
Comparing use case output to truth data
Creating/Updating Docker data volumes with truth data to use in comparisons
12.1. GitHub Actions Workflows
GitHub Actions runs workflows defined by files in the .github/workflows directory of a GitHub repository. Files with the .yml suffix are parsed and GitHub Actions will trigger a workflow run if the triggering criteria is met. Multiple workflows may be triggered by a single event. All workflow runs can be seen on the Actions tab of the repository. Each workflow run is identified by the branch for which it was invoked as well as the corresponding commit message on that branch. In general, a green check mark indicates that all checks for that workflow run passed. A red X indicates that at least one of the jobs failed.
Workflows can run multiple jobs in parallel or serially depending on dependency rules that can be set. Each job can run a series of commands or scripts called steps. Steps can include actions which can be used to perform common tasks. Many useful actions are provided by GitHub and external collaborators. Developers can also write their own custom actions to perform complex tasks to simplify a workflow.
12.1.1. Testing (testing.yml)
This workflow performs a variety of tasks to ensure that changes do not break any existing functionality. See the Testing Workflow for more information.
12.1.2. Documentation (documentation.yml)
METplus documentation is written using Sphinx. The METplus components utilize ReadTheDocs to build and display documentation. However, ReadTheDocs will render the documentation when warnings occur. This GitHub Actions workflow is run to catch/report warnings and errors.
This workflow is only triggered when changes are made to files under the docs directory of the METplus repository. It builds the documentation by running “make clean html” and makes the files available to download at the end of the workflow as a GitHub Actions artifact. This step is no longer mandatory because ReadTheDocs is configured to automatically generate the documentation for each branch/tag and publish it online.
The Makefile that runs sphinx-build was modified to write warnings and errors to a file called warnings.log using the -w argument. This file will be empty if no errors or warnings have occurred in the building of the documentation. If it is not empty, the script called by this workflow will exit with a non-zero value so that the workflow reports a failure.
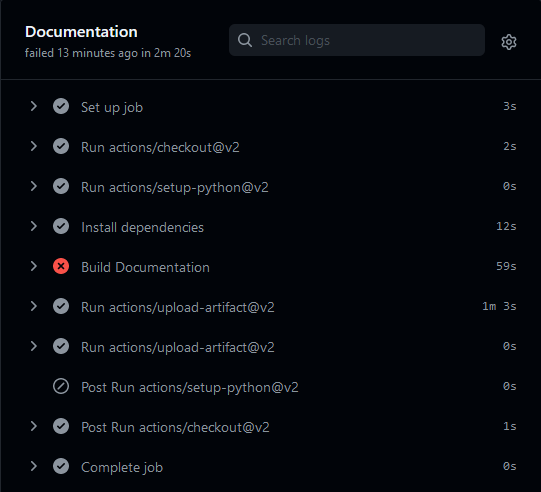
A summary of the lines that contain WARNING or ERROR are output in the GitHub Actions log for easy access. The warnings.log file is also made available as a GitHub Actions artifact so it can be downloaded and reviewed. Artifacts can be found at the bottom of the workflow summary page when the workflow has completed.
12.1.3. SonarQube (sonarqube.yml)
SonarQube is a static code analysis tool used to enhance software code quality and security. The METplus team acknowledges the generous funding from the United States Air Force to support our ongoing use of this important utility.
The sonarqube.yml workflow is defined in all of the METplus component code repositories. This workflow is triggered by a pull_request or push to the develop or main_vX.Y branch and also by manual workflow_dispatch events. However, changes to documentation only or other specific infrastructure directories do not trigger this workflow.
A sonar-project.properties file within each repository defines the configuration of the SonarQube scans for that code base. The SonarQube workflows for the Python-based METplus components are all very similar while the logic for the repositories with compiled code differ.
The SonarQube workflows for the Python-based components (METplus, METplotpy, METcalcpy, and METdataio) run jobs to:
Check out the source code
Set up a Python environment
Run Pytests and create a test code coverage report
Configure the SonarQube properties based on the triggering event
Run a SonarQube scan job provided by SonarSource
Run a SonarQube quality gate check job provided by SonarSource
The quality gate check job pushes the scan results, including code coverage, to a [SonarQube server](https://needham.rap.ucar.edu/) hosted by the METplus team. All memebers of the DTCenter GitHub organization can access this server by logging in with their GitHub credentials.
The SonarQube scans for MET and METviewer require that the code be built, which is done inside a Docker container. However, the results of those Docker-based scans are also pushed to the same SonarQube server.
The scan results for each repository are stored on the server in a project whose name matches the code repository name.
The SonarQube server defines a configurable set of Quality Gate acceptance criteria. For each scan, a reference source is defined and changes are tracked relative to that reference. For example, a new scan of the develop branch is compared to the previous scan of develop, while each pull request scan is compared to the latest scan of the destination branch, typically develop.
SonarQube scans report on the following (listed in approximate order of concern from a security perspective):
Vulnerabilities for security findings
Bugs for reliability findings
Security Hotspots for security findings to be reviewed
Code Smells for maintainability findings
Test code Coverage percentage (if provided to the scan)
Code Duplication percentage
For each finding, the SonarQube scan categorizes it by type, shows its location in the code, and provides detailed information about the reason for the issue, suggestions on how to fix it, and links to additional information.
SonarQube differentiates between New Code and Overall Code where the former shows findings flagged only in new files and lines modified in existing files and the latter shows all findings. Generally speaking, the configurable Quality Gate settings define acceptance criteria based only on findings in New Code.
The Quality Gate check in the SonarQube workflow returns a good status (green checkmark) if the acceptance criteria is met or bad status (red X) if not. Ideally, each change to the code base would result in fewer findings, increased test coverage, and a lower code duplication. Pull requests should never add new Vulnerabilities or Bugs, and the submitter should fix them before their pull request is approved and merged. Introducing new Code Smells is acceptable in certain circumstances. In this case, developers are strongly encouraged to make additional changes that reduce the total number of Code Smells in the Overall Code. While a pull request can add new Code Smells that are not easily fixed, the overall number should be reduced.
Developers are encouaraged to manually run the SonarQube workflow with the GitHub workflow_dispatch option and check the results to confirm the quality of their code before submitting a pull request for review. Developers are encouraged to describe the SonarQube status of their proposed code changes in the body of each pull request. Reviewers should not approve pull requests that introduce new Vulnerabilities or Bugs or increase the number of Code Smells in the Overall Code.
12.1.4. Update Reference Branch (update_reference_branch.yml)
The METplus use case test truth data includes output from use cases that is used to compare with new use case test results to flag any differences. Differences can occur due to changes to the METplus wrappers source code/configuration files or changes to any of its dependent METplus components such as MET, METplotpy, METcalcpy, and METdataio. Differences can also occur when a new use case is added, as the new use case creates output that does not yet exist in the truth dataset.
Once all differences are confirmed to be expected, the reference branch, e.g. develop-ref, needs to be updated. This triggers a Testing Workflow that runs all of the use cases, creates Docker images with the new truth data, and pushes them to DockerHub. This is done so that future pull requests will compare their results to the updated truth dataset.
This process involves creating a pull request with “develop” as the source branch and “develop-ref” as the destination branch. This is done so that the pull request responsible for the changes in the truth data can be referenced to easily track where differences occurred.
The Update Reference Branch workflow is available to handle this step.
Note
IMPORTANT: The latest develop branch testing workflow that contains output differences must be completed before running these instructions.
Ensure that the develop data directory has been updated to include all of the new input data. Check with the reviewers of recent pull requests that add a new use case to confirm that the steps under Update the develop data directory have been completed. If this step has not been completed, then the new use case(s) will fail and the new output data will not be added to the truth data set.
Navigate to https://github.com/dtcenter/METplus/actions/workflows/update_reference_branch.yml or from the METplus GitHub page, click on the Actions tab, then click on “Update Reference Branch” under menu on the left.
Click on the “Run workflow” button on the right.
Click on the Branch pull down and select “develop” unless you are updating the truth data for a bugfix on a main_vX.Y branch.
Enter the pull request numbers that warranted the update. Include the ‘#’ symbol before the number to create a link to the PR. PRs from a repository other than METplus should include the repository name before ‘#’ symbol.
Enter a brief summary of the changes. Developers can navigate to the PRs for more information.
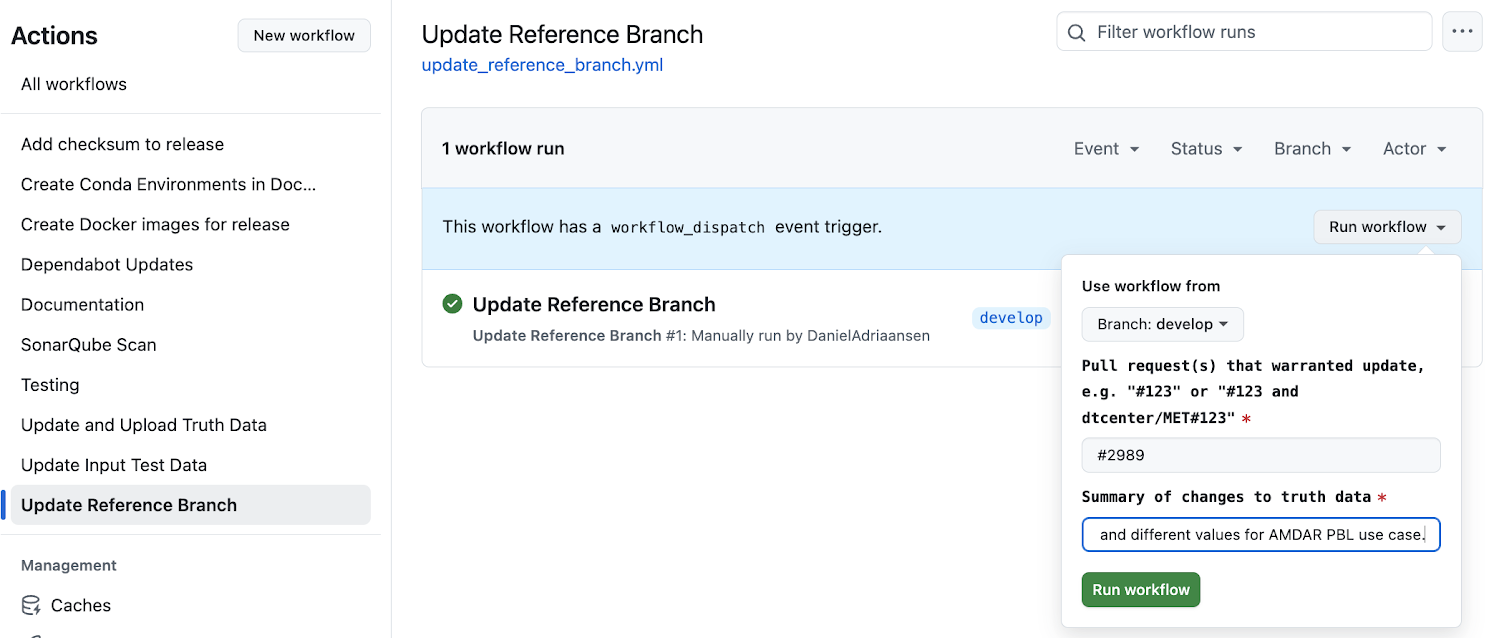
Click the “Run workflow” button.
A new workflow run should appear at the top of the list and complete quickly.
Click on the “Pull Requests” tab. A new pull request should have been created with the information that was entered. Click on the new pull request.
Verify that the information in this pull request is correct. If the “develop” branch was selected in the “Run workflow” menu, then the pull request should show develop-ref <- develop.
Add the appropriate project and milestone values on the right hand side.
If a GitHub issue exists to track the review of the differences, click on the gear icon next to Development on the right side menu and add the issue.
Scroll to the bottom of the pull request and click “Squash and merge.”
Click “Confirm squash and merge.” It is not necessary to wait for the automation checks to complete for this step.
Click the button to delete the update_develop_XXXXXXXX branch.
Monitor the Update Input Test Data workflow run for the develop-ref branch and ensure that all of the use cases run successfully and the final step named “Create Output Docker Data Volumes” completed successfully.
If any use cases fail, check that the input data has been updated following the instructions under Update the develop data directory and rerun all of the jobs of the -ref workflow.
12.1.5. Update Input Test Data (update_input_data.yml)
New/updated input data for a METplus use case is read from the DTC web server as described in the Input Data section of the Adding Use Cases chapter of the METplus Contributor’s Guide. This automatically happens as part of the Testing Workflow when a push event occurs on a dtcenter/METplus branch. This step can be forced by using the Update Input Test Data workflow.
This is workflow is typically used when a new use case is being provided by an external contributor and their pull request is coming from a forked repository. Only dtcenter/METplus workflows have permission to update the input test data.
To force the ingest of this input data, navigate to https://github.com/dtcenter/METplus/actions/workflows/update_input_data.yml . Click on the Run workflow pull-down, type the name of the branch that matches the directory that contains the new data on the DTC web server, and click the Run workflow button.
The value in the branch pull-down under the text that says Use workflow from is ignored if there is a value typed for the branch name. If the branch name exists in the dtcenter/METplus repository, leave the branch name text box blank and select the branch name from the pull-down menu.
Verify that the workflow ran successfully and properly obtained the new data by reviewing the log output from the workflow run.
12.1.6. Update and Upload Truth Data (update_truth_data.yml)
This workflow is triggered by pushes to reference branches (e.g. develop-ref or main_vX.Y-ref). It locates the most recent testing workflow run from the corresponding base branch (e.g. develop or main_vX.Y). For each use case group in which differences were flagged, rerun those use cases to generate update output files, save that output as the new truth dataset, and push the new truth Docker data volume to DockerHub.
12.1.7. Create Conda Environments in Docker (create_conda_envs.yml)
Each use case group runs within a Conda environment. Since dependencies and use case groups change over time, the environment needs to be created for each METplus Coordinated vX.Y release. This workflow can be manually triggered to create these Conda environments and push the resulting images to DockerHub.
See Adding a New Conda Environment for more information.
12.1.8. Add Checksum to Release (release-checksum.yml)
Software releases for the METplus components are created on GitHub. By default, GitHub creates both tar and zip files containing the code for each release. This workflow is triggered by creation of a software release on GitHub. For both the newly created tar and zip files, it generates MD5 checksum files, and uploads them as release assets. The MD5 checksum can be checked by users to validate that the software release they downloaded matches what was originally created by GitHub.
12.1.9. Create Release Docker Images (release-docker-images.yml)
The METplus components build and push Docker images to DockerHub for each release. However, as time passes, those images can grow stale and vulnerabilities can accumulate in the packages and libraries they contain. Rebuilding these images periodically ensures the lastest patches are applied. This workflow is automatically run on a schedule from the default branch of the METplus repositories to recreate Docker images for the currently supported versions of that component. By default, the most recent bugfix version of each supported ‘vX.Y’ release is rebuilt, but this workflow can also be triggered manually for any ‘vX.Y.Z’ version.
12.1.10. Build Docker Image and Trigger METplus Workflow (build_docker_and_trigger_metplus.yml)
Enhancements to and fixes for the METplus components can impact the functionality of the use cases housed in the METplus repository. This workflow is defined and run in the METplus component repositories rather than the top-level METplus repository itself. Any pushes to the code on the develop or main_vX.Y branches trigger this workflow to build an updated Docker image, push it to DockerHub, and send a trigger for the METplus repository to run the testing workflow. This testing workflow run confirms that all of the METplus use cases still run and produce the expected output after the change to this component.
12.1.11. Release Published (release_published.yml) - DEPRECATED
This workflow is no longer required, as Slack now has GitHub integration to automatically create posts on certain events. The workflow YAML file is still found in the repository for reference, but the workflow has been disabled via the Actions tab of the METplus GitHub webpage.
This workflow is triggered when a release is published on GitHub. It uses cURL to trigger a Slack message on the DTC-METplus announcements channel that lists information about the release. A Slack bot was created through the Slack API and the webhook that generated for the Slack channel was saved as a GitHub Secret.
12.2. Testing Workflow
The testing workflow file is found in .github/workflows/testing.yml.
12.2.1. Name
The name of a workflow can be specified to describe an overview of what is run. The following line in the testing.yml file:
name: Testing
defines the workflow identifier that can be seen from the Actions tab on the METplus GitHub page.
12.2.2. Event Control
The on keyword defines which events trigger the workflow to run. There are currently 3 types of events that trigger this workflow: push, pull_request, and workflow_dispatch. The jobs that are run in this workflow depend on which event has triggered it. Many jobs are common to multiple events. To avoid creating multiple workflow .yml files that contain redundant jobs, an additional layer of control is added within this workflow. See Job Control for more information.
12.2.2.1. Push
on:
push:
branches:
- develop
- develop-ref
- 'feature_*'
- 'main_*'
- 'bugfix_*'
paths-ignore:
- 'docs/**'
pull_request:
types: [opened, synchronize, reopened]
branches:
- develop
- 'main_*'
paths-ignore:
- 'docs/**'
workflow_dispatch:
inputs:
repository:
description: 'Repository that triggered workflow'
required: true
sha:
description: 'Commit hash that triggered the event'
required: true
ref:
description: 'Branch that triggered event'
required: true
actor:
description: 'User that triggered the event'
pusher_email:
description: 'Email address of user who triggered push event'
This configuration tells GitHub Actions to trigger the workflow when changes are pushed to the repository and the following criteria are met:
The branch is named develop or develop-ref.
The branch starts with feature_, main_, or bugfix_.
Changes were made to at least one file that is not in the docs directory.
12.2.2.2. Pull Request
pull_request:
types: [opened, reopened, synchronize]
paths-ignore:
- 'docs/**'
This configuration tells GitHub Actions to trigger the workflow for pull requests in the repository and the following criteria are met:
The pull request was opened, reopened, or synchronized.
Changes were made to at least one file that is not in the docs directory.
The synchronize type triggers a workflow for every push to a branch that is included in an open pull request. If changes were requested in the pull request review, a new workflow will be triggered for each push. To prevent many workflows from being triggered, developers are encouraged to limit the number of pushes for open pull requests. Note that pull requests can be closed until the necessary changes are completed, or Commit Message Keywords can be used to suppress the testing workflow.
12.2.2.3. Workflow Dispatch
workflow_dispatch:
inputs:
repository:
description: 'Repository that triggered workflow'
required: true
sha:
description: 'Commit hash that triggered the event'
required: true
ref:
description: 'Branch that triggered event'
required: true
actor:
description: 'User that triggered the event'
This configuration enables manual triggering of this workflow. It allows other GitHub repositories such as MET, METplotpy, and METcalcpy to trigger this workflow. It lists the input values that are passed from the external repository. The inputs include:
The repository that triggered the workflow, such as dtcenter/MET
The commit hash in the external repository that triggered the event
The reference (or branch) that triggered the event, such as refs/heads/develop
The GitHub username that triggered the event in the external repository (optional)
The MET, METcalcpy, and METplotpy repositories are configured to trigger this workflow since they are used in 1 or more METplus use cases. Currently all 3 repositories only trigger when changes are pushed to their develop branch.
Future work is planned to support main_v* branches, which will involve using the ‘ref’ input to determine what to obtain in the workflow. For example, changes pushed to dtcenter/MET main_v10.1 should trigger a testing workflow that runs on the METplus main_v4.1 branch.
12.2.3. Jobs
The jobs keyword is used to define the jobs that are run in the workflow. Each item under jobs is a string that defines the ID of the job. This value can be referenced within the workflow as needed. Each job in the testing workflow is described in its own section.
12.2.4. Event Info
event_info:
name: "Trigger: ${{ github.event_name != 'workflow_dispatch' && github.event_name || github.event.inputs.repository }} ${{ github.event_name != 'workflow_dispatch' && 'local' || github.event.inputs.actor }} ${{ github.event_name != 'workflow_dispatch' && 'event' || github.event.inputs.sha }}"
runs-on: ubuntu-latest
steps:
- name: Print GitHub values for reference
env:
GITHUB_CONTEXT: ${{ toJson(github) }}
run: echo "$GITHUB_CONTEXT"
This job contains information on what triggered the workflow. The name of the job contains complex logic to cleanly display information about an event triggered by an external repository when that occurs. Otherwise, it simply lists the type of local event (push or pull_request) that triggered the workflow.
12.2.4.1. Workflow Triggered by Another Repository:
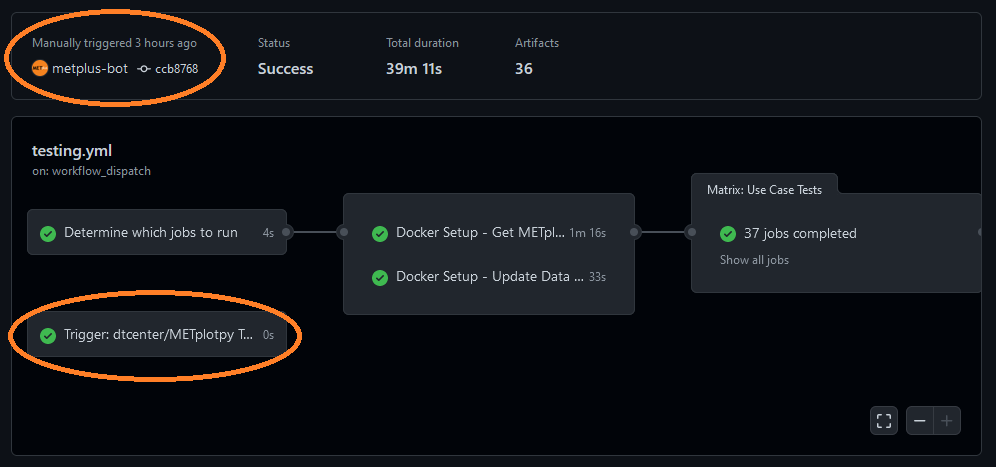
12.2.4.2. Workflow Triggered by a Push to the METplus Repository:
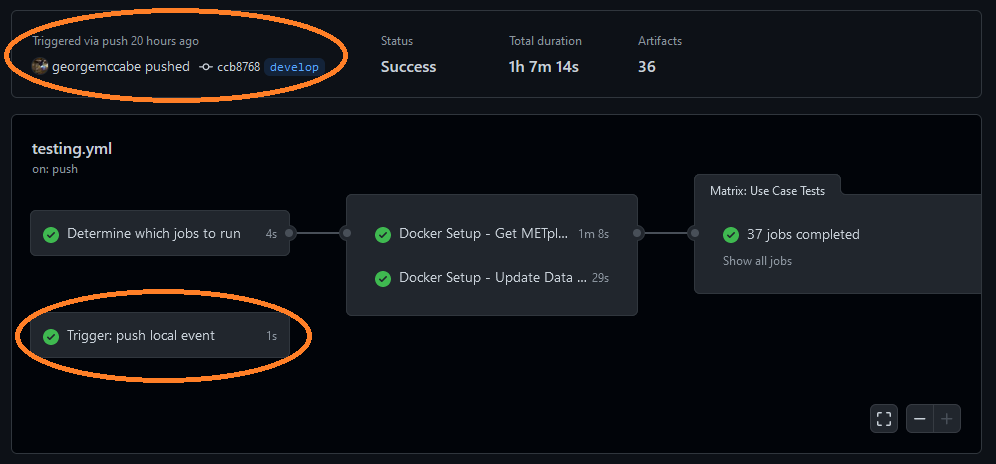
It also logs all of the information contained in the ‘github’ object that includes all of the available information from the event that triggered the workflow. This is useful to see what information is available to use in the workflow based on the event.
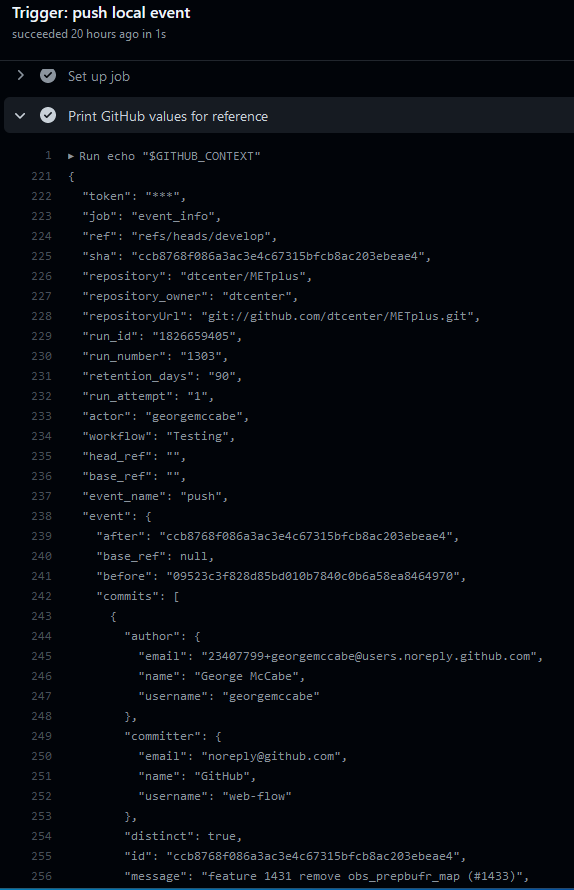
12.2.5. Job Control
job_control:
name: Determine which jobs to run
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v2
- name: Set job controls
id: job_status
run: .github/jobs/set_job_controls.sh
env:
commit_msg: ${{ github.event.head_commit.message }}
outputs:
matrix: ${{ steps.job_status.outputs.matrix }}
run_some_tests: ${{ steps.job_status.outputs.run_some_tests }}
run_get_image: ${{ steps.job_status.outputs.run_get_image }}
run_get_input_data: ${{ steps.job_status.outputs.run_get_input_data }}
run_diff: ${{ steps.job_status.outputs.run_diff }}
run_save_truth_data: ${{ steps.job_status.outputs.run_save_truth_data }}
external_trigger: ${{ steps.job_status.outputs.external_trigger }}
branch_name: ${{ steps.job_status.outputs.branch_name }}
This job runs a script called set_job_controls.sh that parses environment variables set by GitHub Actions to determine which jobs to run. There is Default Behavior based on the event that triggered the workflow and the branch name. The last commit message before a push event is also parsed to look for Commit Message Keywords that can override the default behavior.
The script also calls another script called get_use_cases_to_run.sh that reads a JSON file that contains the use case test groups. The job control settings determine which of the use case groups to run. See Use Case Groups for more information.
12.2.5.1. Output Variables
The step that calls the job control script is given an identifier using the id keyword:
id: job_status
run: .github/jobs/set_job_controls.sh
Values from the script are set as output variables using the following syntax:
echo ::set-output name=run_get_image::$run_get_image
In this example, an output variable named run_get_image (set with name=run_get_image) is created with the value of a variable from the script with the same name (set after the :: characters). The variable can be referenced elsewhere within the job using the following syntax:
${{ steps.job_status.outputs.run_get_image }}
The ID of the step is needed to reference the outputs for that step.
Note
This notation should be referenced directly in the workflow YAML file and not inside a script that is called by the workflow.
To make the variable available to other jobs in the workflow, it will need to be set in the outputs section of the job:
outputs:
run_get_image: ${{ steps.job_status.outputs.run_get_image }}
The variable run_get_image can be referenced by other jobs that include job_status as a job that must complete before starting using the needs keyword:
get_image:
name: Docker Setup - Get METplus Image
runs-on: ubuntu-latest
needs: job_control
if: ${{ needs.job_control.outputs.run_get_image == 'true' }}
Setting needs: job_control tells the get_image job to wait until the job_control job has completed before running. Since this is the case, this job can reference output from that job in the if value to determine if the job should be run or not.
12.2.5.2. Default Behavior
12.2.5.2.1. On Push
When a push event occurs the default behavior is to run the following:
Create/Update the METplus Docker image.
Look for new input data.
Run unit tests.
Run any use cases marked to run (see Use Case Tests).
If the push is on the develop or a main_vX.Y branch, then all of the use cases are run.
Default behavior for push events can be overridden using Commit Message Keywords.
12.2.5.2.2. On Pull Request
When a pull request is created into the develop branch or a main_vX.Y branch, additional jobs are run in automation. In addition to the jobs run for a push, the scripts will:
Run all use cases
Compare use case output to truth data
12.2.5.2.3. On Push to Reference Branch
Branches with a name that ends with -ref contain the state of the repository that will generate output that is considered “truth” data. In addition to the jobs run for a push, the scripts will:
Run all use cases.
Create/Update Docker data volumes that store truth data with the use case output.
See Create/Update Output Data Volumes for more information.
12.2.5.3. Commit Message Keywords
The automation logic reads the commit message for the last commit before a push. Keywords in the commit message can override the default behavior. Here is a list of the currently supported keywords and what they control:
ci-skip-all: Don’t run anything - skip all automation jobs.
ci-skip-use-cases: Don’t run any use cases.
ci-skip-unit-tests: Don’t run the Pytest unit tests.
ci-run-all-cases: Run all use cases.
ci-run-diff: Obtain truth data and run diffing logic for use cases that are marked to run.
ci-run-all-diff: Obtain truth data and run diffing logic for all use cases.
12.2.6. Create/Update METplus Docker Image
get_image:
name: Docker Setup - Get METplus Image
runs-on: ubuntu-latest
needs: job_control
if: ${{ needs.job_control.outputs.run_get_image == 'true' }}
steps:
- uses: actions/checkout@v2
- uses: actions/setup-python@v2
with:
python-version: '3.6'
- name: Get METplus Image
run: .github/jobs/docker_setup.sh
env:
DOCKER_USERNAME: 'dtcenter'
DOCKER_PASSWORD: ${{ secrets.DOCKER_TOKEN }}
#SET_MET_IMAGE: met:10.0.0
This job calls the docker_setup.sh script. This script builds a METplus Docker image and pushes it to DockerHub. The image is pulled instead of built in each test job to save execution time. The script attempts to pull the appropriate Docker image from DockerHub (dtcenter/metplus-dev:BRANCH_NAME) if it already exists so that unchanged components of the Docker image do not need to be rebuilt. This reduces the time it takes to rebuild the image for a given branch on a subsequent workflow run.
12.2.6.1. DockerHub Credentials
The credentials needed to push images to DockerHub are stored in Secret Environment Variables for the repository. These variables are passed into the script that needs them using the env keyword.
12.2.6.2. Force MET Version Used for Tests
The tests typically use the develop version tag of the MET Docker image for development testing. If testing is done on a stable release, then the corresponding MET stable release will be used. However, there may be an instance where a change in MET breaks something in another METplus component, i.e. METplotpy or METviewer, until a corresponding change is made to that component. If this occurs then some of the METplus use cases may break.
Another situation that may require a different MET Docker image is if there are changes in a MET feature or bugfix branch that are needed to test changes in METplus.
To allow the tests to run successfully in these cases, an option was added to force a specific MET Docker image to be used to build the METplus Docker image that is used for testing.
In the testing.yml workflow file, there is a commented variable called SET_MET_IMAGE that can be uncommented and set the MET Docker image to use. This variable is found in the get_image job under the env section for the step named “Get METplus Image.”
The format of the value is <REPO>:<TAG> where the DockerHub repo used is dtcenter/<REPO> and the tag used is <TAG>.
Stable releases of MET are found in the dtcenter/met DockerHub repo and are named using the X.Y.Z version of the release, so setting SET_MET_IMAGE=met:11.1.0 will use dtcenter/met:11.1.0.
Development versions of MET are found in the dtcenter/met-dev DockerHub repo and are named using the branch name, so setting SET_MET_IMAGE=met-dev:feature_XYZ_info will use dtcenter/met-dev:feature_XYZ_info.
12.2.7. Create/Update Docker Data Volumes
update_data_volumes:
name: Docker Setup - Update Data Volumes
runs-on: ubuntu-latest
needs: job_control
if: ${{ needs.job_control.outputs.run_get_input_data == 'true' }}
steps:
- uses: dtcenter/metplus-action-data-update@v1
with:
docker_name: 'dtcenter'
docker_pass: ${{ secrets.DOCKER_TOKEN }}
repo_name: ${{ github.repository }}
data_prefix: sample_data
branch_name: ${{ needs.job_control.outputs.branch_name }}
docker_data_dir: /data/input/METplus_Data
data_repo_dev: metplus-data-dev
data_repo_stable: metplus-data
use_feature_data: true
The METplus use case tests obtain input data from Docker data volumes. Each use case category that corresponds to a directory in parm/use_cases/model_applications has its own data volume that contains all of the data needed to run those use cases. The MET Tool Wrapper use cases found under parm/use_cases/met_tool_wrapper also have a data volume. These data are made available on the DTC web server.
This job utilizes the dtcenter/metplus-action-data-update Github Action. The logic in this action checks if the tar file on the DTC web server that contains the data for a use case category has changed since the corresponding Docker data volume has been last updated. If it has, then the Docker data volume is regenerated with the new data. This action is also used by the MET repository.
When new data is needed for a new METplus use case, a directory that is named after a feature branch is populated with the existing data for the use case category and the new data is added there. This data is used for testing the new use case in the automated tests. When the pull request for the new use case is approved, the new data is moved into the version of the data that corresponds to the upcoming release (i.e. v4.1) so that it will be available for future tests. More details on this process can be found in the Input Data section of the Add Use Cases chapter of the Contributor’s Guide.
12.2.8. Unit Tests
Unit tests are run via pytest. Groups of pytests are run in the ‘pytests’ job. The list of groups that will be run in the automated tests are found in .github/parm/pytest_groups.txt. See Unit Tests for more information on pytest groups.
Items in pytest_groups.txt can include:
* A single group marker name, i.e. wrapper_a
* Multiple group marker names separated by _or_, i.e. plotting_or_long
* A group marker name to exclude starting with not_, i.e. not_wrapper
All pytest groups are currently run in a single GitHub Actions job. This was done because the existing automation logic builds a Docker environment to run the tests and each testing environment takes a few minutes to create (future improvements may speed up execution time by running the pytests directly in the GitHub Actions environment instead of Docker). Running the pytests in smaller groups serially takes substantially less time than calling all of the existing pytests in a single call to pytest, so dividing tests into groups is recommended to improve performance. Searching for the string “deselected in” in the pytests job log can be used to see how long each group took to run.
Future enhancements could be made to save and parse this information for each run to output a summary at the end of the log file to more easily see which groups could be broken up to improve performance.
12.2.9. Use Case Tests
12.2.9.1. All Use Cases
All of the existing use cases are listed in all_use_cases.txt, found in internal/tests/use_cases.
The file is organized by use case category. Each category starts a line that following the format:
Category: <category>
where <category> is the name of the use case category. See Use Case Categories for more information. If a use case is being added will go into a new category, a new category definition line will have to be added to this file and the new use case added under it. Each use case in that category will be found on its own line after this line. The use cases can be defined using the following formats:
<index>::<name>::<config_args>
<index>::<name>::<config_args>::<dependencies>
12.2.9.1.1. index
The index is the number associated with the use case so it can be referenced easily. The first index number in a new category should be 0. Each use case added should have an index that is one greater than the previous. If it has been determined that a use case cannot run in the automated tests, then the index number should be replaced with “#X” so that it is included in the list for reference but not run by the tests.
12.2.9.1.2. name
This is the string identifier of the use case. The name typically matches the use case configuration filename without the .conf extension.
Example:
PointStat_fcstGFS_obsGDAS_UpperAir_MultiField_PrepBufr
12.2.9.1.3. config_args
This is the path of the config file used for the use case relative to parm/use_cases.
Example:
model_applications/medium_range/PointStat_fcstGFS_obsGDAS_UpperAir_MultiField_PrepBufr.conf
If the use case contains multiple configuration files, they can be listed separated by commas.
Example:
met_tool_wrapper/GridStat/GridStat.conf,met_tool_wrapper/GridStat/GridStat_forecast.conf,met_tool_wrapper/GridStat/GridStat_observation.conf
12.2.9.1.4. dependencies
If there are additional dependencies required to run the use case, such as a different Python environment, a list of keywords separated by commas can be provided. The Use Case Dependencies section contains information on the keywords that can be used.
Example:
cycloneplotter_env
12.2.9.2. Use Case Dependencies
12.2.9.2.1. Conda Environments
The keywords that end with _env are Python environments created in Docker images using Conda that can be used to run use cases. These images are stored on DockerHub in dtcenter/metplus-envs and are named with a tag that corresponds to the keyword without the _env suffix. The environments were created using Docker commands via scripts that are found in internal/scripts/docker_env. Existing keywords that set up Conda environments used for use cases, with the versions of Python packages they contain are:
py_embed_base_env
Python 3.12.0
xarray 2025.1.2
netcdf4 1.7.2
pyyaml 6.0.2
Note: Adding the py_embed_base_env keyword is not necessary if the py_embed keyword is used (see Other Keywords). A Python Embedding use case that only requires the minimum packages needed to run Python Embedding can use the version of Python that MET was installed with. The list of packages is only included here for reference, as other environments use this environment as a base.
cfgrib_env
Python 3.12.0
metpy 1.6.3
netcdf4 1.7.2
cfgrib 0.9.15
pygrib 2.1.6
cycloneplotter_env
Python 3.12.0
cartopy 0.24.0
matplotlib 3.10.0
pandas 2.2.3
geovista_env
Python 3.12.0
geovista 0.5.3
xarray 2025.1.2
iris 3.11.1
h5py_env
All packages in py_embed_base_env
h5py 3.12.1
icecover_env
All packages in py_embed_base_env
xarray 2025.1.2
pyresample 1.32.0
scikit-learn 1.6.1
pyproj 3.7.0
metdataio_env
Python 3.12.0
pymysql 1.1.1
pyyaml 6.0.2
xarray 2025.1.2
lxml 5.3.0
netcdf4 1.7.2
metplotpy_env
Python 3.12.0
matplotlib 3.10.0
scipy 1.15.1
plotly 6.1.1
xarray 2025.1.2
netcdf4 1.7.2
pyyaml 6.0.2
python-kaleido 1.0.0
imageio 2.37.0
imutils 0.5.4
scikit-image 0.25.1
pint 0.24.4
metpy 1.6.3
cartopy 0.24.0
mp_analysis_env
All packages in metplotpy_env
lxml 5.3.0
pymysql 1.1.1
netcdf4_env
Python 3.12.0
netcdf4 1.7.2
pandac_env
All packages in metplotpy_env
pygrib 2.1.6
pygrib_env
All packages in py_embed_base_env
pygrib 2.1.6
metpy 1.6.3
spacetime_env
NOTE: This env is not used because pyngl is not supported in Python 3.12.
Python 3.10.4
netCDF4 1.5.8
xarray 2022.3.0
scipy 1.8.1
matplotlib 3.5.2
pyngl 1.6.1
pyyaml 6.0
swpc_metpy_env
Python 3.12.0
xarray 2025.1.2
netcdf4 1.7.2
pyyaml 6.0.2
scipy 1.15.1
metpy 1.6.3
weatherregime_env
All packages in metplotpy_env
scikit-learn 1.6.1
eofs 2.0.0
cmocean 4.0.3
xesmf_env
Python 3.12.0
netcdf4 1.7.2
xarray 2025.1.2
xesmf 0.8.8
esmf 8.7.0
zarr_env
All packages in py_embed_base_env
zarr 3.2.1
Example:
mp_analysis_env
The above example uses the Conda environment in dtcenter/metplus-envs:mp_analysis.vX.Y to run a user script where X.Y is the version of METplus when the environment was lasted updated, e.g. 5.1. Note that only one dependency that contains the _env suffix can be supplied to a given use case.
If a new use case requires packages that are not included in these environments, see Adding a New Conda Environment.
12.2.9.2.2. Other Environments
A few of the environments do not contain Conda environments and are handled a little differently.
gempak_env - Used if GempakToCF.jar is needed for a use case to convert GEMPAK data to NetCDF format so it can be read by the MET tools. Instead of creating a Python environment to use for the use case, this Docker image installs Java and obtains the GempakToCF.jar file. When creating the Docker container to run the use cases, the necessary Java files are copied over into the container that runs the use cases so that the JAR file can be run by METplus wrappers.
gfdl-tracker_env - Contains the GFDL Tracker application that is used by the GFDLTracker wrapper use cases.
12.2.9.2.3. Other Keywords
Besides specifying Python environments, there are additional keywords that can be used to set up the environment to run a use case:
py_embed - Used if a different Python environment is required to run a Python Embedding script. If this keyword is included with a Python environment, then the MET_PYTHON_EXE environment variable will be set to specify the version of Python3 that is included in that environment.
Example:
pygrib_env,py_embed
In this example, the dtcenter/metplus-envs:pygrib environment is used to run the use case. Since py_embed is also included, then the following will be added to the call to run_metplus.py so that the Python embedding script will use the pygrib environment to run:
user_env_vars.MET_PYTHON_EXE=/usr/local/envs/pygrib/bin/python3
Please see the MET User’s Guide for more information on how to use Python Embedding.
metviewer - Used if METviewer should be made available to the use case. This is typically added for a METdbLoad use case that needs to populate a database with MET output.
metplus - Used if a user script needs to call utility functions from the metplus Python package. This keyword simply adds the METplus source code directory to the PYTHONPATH so that the metplus.util functions can be imported. Note that this keyword is not needed unless a different Python environment is specified with a “_env” keyword. The version of Python that is used to run typical use cases has already installed the METplus Python package in its environment, so the package can be imported easily.
metdatadb - Used if the METdataio repository is needed to run. Note that this is only needed if using a Conda environment other than metdatadb_env. The repository Python code will be installed in the Python environment.
cartopy - Used if cartopy 0.18.0 is needed in the Conda environment. Cartopy uses shapefiles that are downloaded as needed. The URL that is used to download the files has changed since cartopy 0.18.0 and there have been issues where the files cannot be obtained. To remedy this issue, the METplus Docker images, which contain the Conda environments, including Cartopy, have been modified to download the necessary shape files so that they will always be available. These files need to be copied from the Docker environment image into the testing image. When this keyword is found in the dependency list, a different Dockerfile (Dockerfile.run_cartopy found in .github/actions/run_tests) is used to create the testing environment and copy the required shapefiles into place.
12.2.9.2.4. Adding a New Conda Environment
In METplus v4.0.0 and earlier, a list of Python packages were added to use cases that required additional packages. These packages were either installed with pip3 or using a script. This approach was very time consuming as some packages take a very long time to install in Docker. The new approach involves creating Docker images that use Conda to create a Python environment that can run the use case. To see what is available in each of the existing Python environments, refer to the comments in the scripts found in internal/scripts/docker_env/scripts.
If none of these environments contain the package requirements needed to run a new use case, a new environment must be added by a METplus developer. See the instructions below or create a new discussion on the METplus GitHub Discussions forum.
A README.md file can be found in internal/scripts/docker_env that provides commands that can be run to recreate a Docker image if the conda environment needs to be updated. Please note that Docker must be installed on the workstation used to create new Docker images and a DockerHub account with access to the dtcenter repositories must be used to push Docker images to DockerHub.
The README.md file also contains commands to create a conda environment that is used for the tests locally. Any base conda environments, such as metplus_base and py_embed_base, must be created locally first before creating an environment that builds upon these environments. Please note that some commands in the scripts are specific to the Docker environment and may need to be rerun to successfully build the environment locally.
If a new use case requires a Python package that is not available in any of the existing Conda environments, a new environment should be created. The following steps should be taken to add a new environment:
Create a new script in
internal/scripts/docker_env/scripts/{ENV_NAME}_env.shthat either creates a new conda environment or clones an existing one to add new packages. Typically environments are based onpy_embed_baseif they will be used for MET Python Embedding or based onmetplotpyormp_analysisif they use METplus Analysis functionality. Currently, most other environments are based onmetplus_basebecause at a minimum they needpython-dateutil. Unless a specific version is required, it is recommended to use the version that Conda installs by default. If the version number is not known, do not specify a version initially, then add it to the script later. See the step about creating environments in GitHub Actions for more information.Add a section to the
README.mdfile ininternal/scripts/docker_envto include instructions on how to create the environment in Docker and locally.Create a new job in
.github/workflows/create_conda_envs.ymlso that the environment can be created in GitHub Actions. The job should be formatted so the job name matches the environment name and is checked in theifcondition. The dependency (needs) should also include the base environment and the Dockerfile should be chosen based on the environment criteria (e.g.metplus_base,py_embed_base, orDockerfile.cartopyif it contains cartopy).After these files are added, run the Create Conda Envs GHA workflow from the branch where the files were added via
workflow_dispatch, providing the name of the new environment to create. This workflow should run without errors. If the version number was not specified for any of the packages, review the log output to determine which version was used. Update the script to specify this version to ensure reproducibility. For example, if the log output includes something like this:#9 61.62 + zarr 3.2.1 pyhc364b38_0 conda-forge 368kBthen update the script to specify
zarr==3.2.1.Add information about the new environment, including all version numbers, to the Conda Environments section.
Installing METplus Components
The scripts used to create the Python environment Docker images do not install any METplus components, such as METplotpy, METcalcpy, METdataio, and METplus, in the Python environment that may be needed for a use case. This is done because the automated tests will install and use the latest version (develop) of the packages to ensure that any changes to those components do not break any existing use cases. These packages will need to be installed by the user and need to be updated manually. To install these packages, activate the Conda environment, obtain the source code from GitHub, and run “pip3 install .” in the top level directory of the repository.
Example:
conda activate weatherregime
git clone git@github.com:dtcenter/METplotpy
cd METplotpy
git checkout develop
git pull
pip3 install .
Cartopy Shapefiles
The cartopy python package automatically attempts to download shapefiles as needed. The URL that is used in cartopy version 0.18.0 and earlier no longer exists, so use cases that need these files will fail if they are not found locally. If a conda environment uses cartopy, these shapefiles may need to be downloaded by the user running the use case even if the conda environment was created by another user. Cartopy provides a script that can be used to obtain these shapefiles from the updated URL:
wget https://raw.githubusercontent.com/SciTools/cartopy/master/tools/cartopy_feature_download.py
python3 cartopy_feature_download.py cultural physical cultural-extra
12.2.9.3. Use Case Groups
The use cases that are run in the automated test suite are divided into groups that can be run concurrently.
The use_case_groups.json file (found in .github/parm) contains a list of the use case groups to run together. In METplus version 4.0.0 and earlier, this list was found in the .github/workflows/testing.yml file.
Each use case group is defined with the following format:
{
"category": "<CATEGORY>",
"index_list": "<INDEX_LIST>",
"run": <RUN_STATUS>
}
<CATEGORY> is the category group that the use case is found under in the all_use_cases.txt file (see All Use Cases).
<INDEX_LIST> is a list of indices of the use cases from all_use_cases.txt to run in the group. This can be a single integer, a comma-separated list of integers, and a range of values with a dash, i.e. 0-3.
<RUN_STATUS> is a boolean (true/false) value that determines if the use case group should be run. If the workflow job controls are not set to run all of the use cases, then only use case groups that are set to true are run.
Example:
{
"category": "climate",
"index_list": "2",
"run": true
}
This example defines a use case group that contains the climate use case with index 2 and is marked to run for every push.
12.2.9.3.1. Subset Category into Multiple Tests
Use cases can be separated into multiple test jobs. In the index_list value, define the cases to run for the job. Use cases are numbered starting with 0 and correspond to the number set in the all_use_cases.txt file.
The argument supports a comma-separated list of numbers. Example:
{
"category": "data_assimilation",
"index_list": "0,2,4",
"run": false
},
{
"category": "data_assimilation",
"index_list": "1,3",
"run": false
},
The above example will run a job with data_assimilation use cases 0, 2, and 4, then another job with data_assimilation use cases 1 and 3.
It also supports a range of numbers separated with a dash. Example:
{
"category": "data_assimilation",
"index_list": "0-3",
"run": false
},
{
"category": "data_assimilation",
"index_list": "4-5",
"run": false
},
The above example will run a job with data_assimilation 0, 1, 2, and 3, then another job with data_assimilation 4 and 5.
Use a combination of commas and dashes to define the list of cases to run. Example:
{
"category": "data_assimilation",
"index_list": "0-2,4",
"run": false
},
{
"category": "data_assimilation",
"index_list": "3",
"run": false
},
The above example will run data_assimilation 0, 1, 2, and 4 in one job, then data_assimilation 3 in another job.
12.2.9.3.2. Disabling Use Cases
Sometimes use cases should not run in the automated test suite. For example, changes to another repository may break a use case and prevent it from running successfully until a fix can be applied. In the meantime, to prevent the use case(s) from failing in the automated tests, a use case group can be disabled by adding “disabled”: true in use_case_groups.json:
{
"category": "short_range",
"index_list": "14",
"disabled": true,
"run": true
},
It is recommended to add this key/value pair before the run key/value to avoid having to add a comma to the end of the run value.
If the disabled value is set to true, then the use case group will not run even if the run attribute is set to true.
12.2.9.4. Run Use Cases
The use_case_tests job is duplicated for each use case group using the strategy -> matrix syntax:
strategy:
fail-fast: false
matrix: ${{fromJson(needs.job_control.outputs.matrix)}}
fail-fast is set to false so that the rest of the use case test jobs will run even when one of them fails. The matrix value is a list of use case categories and indices that is created in the Job Control job. Each value in the list is referenced in the job steps with ${{ matrix.categories }}:
- name: Run Use Cases
uses: ./.github/actions/run_tests
id: run_tests
with:
categories: ${{ matrix.categories }}
The logic that runs the use cases is contained in a custom GitHub Action that is found in the METplus repository.
12.2.9.4.1. Obtaining Input Data
Each use case category has a corresponding Docker data volume that contains the input data needed to run all of the use cases. The data volume is obtained from DockerHub and mounted into the container that will run the use cases using the --volumes-from argument to the docker run command.
12.2.9.4.2. Build Docker Test Environment
A Docker multi-stage build is used to create the Docker environment to run the use cases. The Docker images that contain the Use Case Dependencies are built and the relevant files (such as the Conda environment files) are copied into the METplus image so that they will be available when running the use cases.
12.2.9.4.3. Setup Use Case Commands
Before run_metplus.py is called to run the use case, some other commands are run in the Docker container. For example, if another METplus Python component such as METcalcpy, METplotpy, or METdataio are required for the use case, the develop branch of those repositories are obtained the Python code is installed in the Python (Conda) environment that will be used to run the use case.
12.2.9.4.4. Run the Use Cases
The run_metplus.py script is called to run each use case. The OUTPUT_BASE METplus configuration variable is overridden to include the use case name identifier defined in the All Use Cases file to isolate all of the output for each use case. If any of the use cases contain an error, then the job for the use case group will fail and display a red X next to the job on the GitHub Actions webpage.
12.2.9.5. Difference Tests
After all of the use cases in a group have finished running, the output that was generated is compared to the truth data to determine if any of the output was changed. The truth data for each use case group is stored in a Docker data volume on DockerHub. The diff_util.py script (found in metplus/util) is run to compare all of the output files in different ways depending on the file type.
The logic in this script could be improved to provide more robust testing. For example, the logic to compare images has been disabled because the existing logic was reporting false differences.
If any differences were found, then the files that contained the differences are copied into a directory so they can be made available in an artifact. The files are renamed to include an identifier just before the extension so that it is easy to tell which file came from the truth data and which came from the new output.
12.2.10. Create/Update Output Data Volumes
create_output_data_volumes:
name: Create Output Docker Data Volumes
runs-on: ubuntu-latest
needs: [use_case_tests]
if: ${{ needs.job_control.outputs.run_save_truth_data == 'true' }}
steps:
- uses: actions/checkout@v2
- uses: actions/download-artifact@v2
- run: .github/jobs/create_output_data_volumes.sh
env:
DOCKER_USERNAME: 'dtcenter'
DOCKER_PASSWORD: ${{ secrets.DOCKER_TOKEN }}
Differences in the use case output may be expected. The most common difference is new data from a newly added use case that is not found in the truth data. If all of the differences are determined to be expected, then the truth data must be updated so that the changes are included in future difference tests. All of the artifacts with a name that starts with use_cases_ are downloaded in this job. Data from each group is copied into a Docker image and pushed up to DockerHub, replacing the images that were used for the difference tests. See On Push to Reference Branch for information on which events trigger this job.
12.2.11. Output (Artifacts)
12.2.11.1. Error Logs
If there are errors in any of the use cases, then the log file from the run is copied into a directory that will be made available at the end of the workflow run as a downloadable artifact. This makes it easier to review all of the log files that contain errors.
12.2.11.2. Output Data
All of the output data that is generated by the use case groups are saved as downloadable artifacts. Each output artifact name starts with use_cases_ and contains the use case category and indices. This makes it easy to obtain the output from a given use case to review.
12.2.11.3. Diff Data
When differences are found when comparing the new output from a use case to the truth data, an artifact is created for the use case group. It contains files that differ so that the user can download and examine them. Files that are only found in one or the other are also included.
12.3. Custom GitHub Actions
Custom actions are designed to handle common functionality that is needed by multiple GitHub Actions workflows across multiple METplus GitHub repositories. Each custom action is stored in its own GitHub repository. Navigate to the GitHub repository for a custom action to learn more about using it.
12.3.1. Free Disk Space
Removes files that are not used by METplus workflows from the GitHub Actions runner environment to free up disk space.
dtcenter/metplus-action-free-disk-space
Warning
DO NOT USE THIS ACTION WITH SELF-HOSTED RUNNERS!
12.3.2. Scan Docker Images
Scans Docker images for Common Vulnerabilities and Exposures (CVEs).
12.3.3. Data Update
Query web server and update data volumes used for testing.
12.3.4. Trigger METplus Use Cases
Trigger a METplus testing workflow to ensure that changes to other METplus component repositories do not break METplus use case functionality.
12.3.5. Create Checksum for Release
Add a checksum to a release